不同的场景,可能意味着不同的东西,包括:
- 一种抽象规范
- 一种规范实现
- 一个运行实例
生命周期
从main()函数开始,当所以非守护进程退出,或System.exit()时结束
体系结构
需要先明确: JVM规范定义的子系统、运行时数据区等,都只是一个抽象定义,只要能满足这些外部的行为,内部的具体实现完全可以由设计者决定。
系统运行时结构
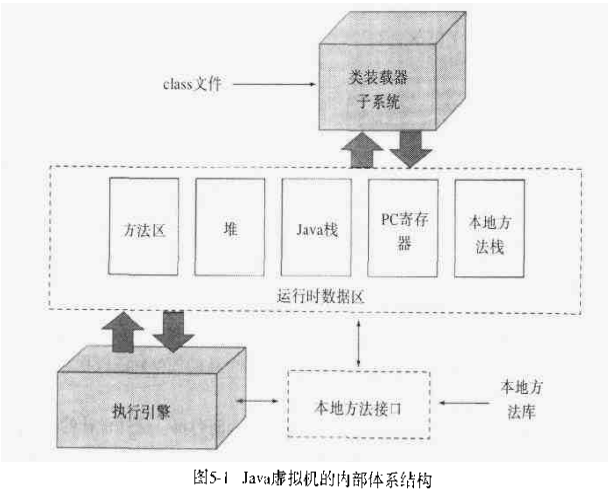
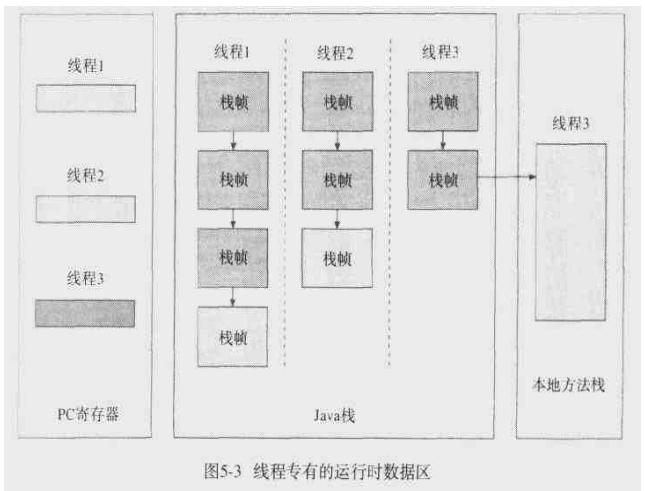
Java栈运行时结构
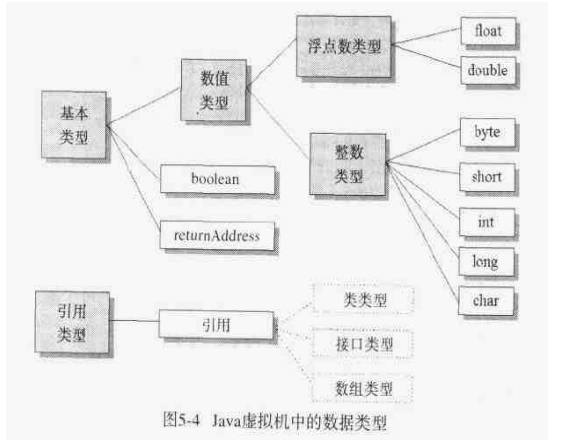
数据类型
字(word) 一个字没有固定长度,但要求:
- 一个字可以表示int,byte,float等
- 两个字可以表示long,double
- 一个字可以表示一个引用
所以,通常一个字最少32bit。一般是特定平台上的指针长度。
特殊类型
- boolean用byte或int表示
- returnAddress,只用于虚拟机内部
引用类型
三种引用
- 类类型
- 接口类型
- 数组类型
还有一个特殊的null值
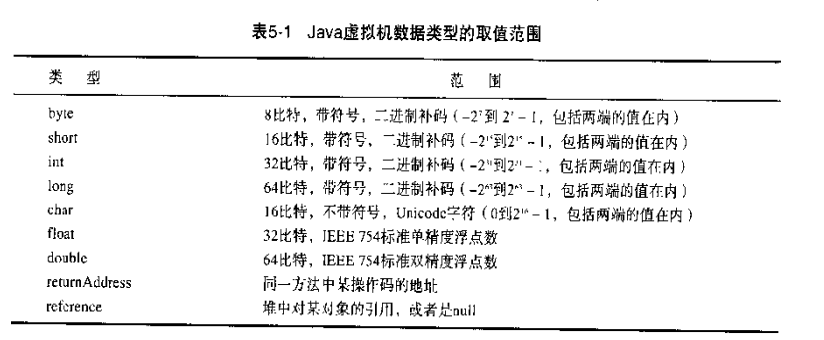
取值范围
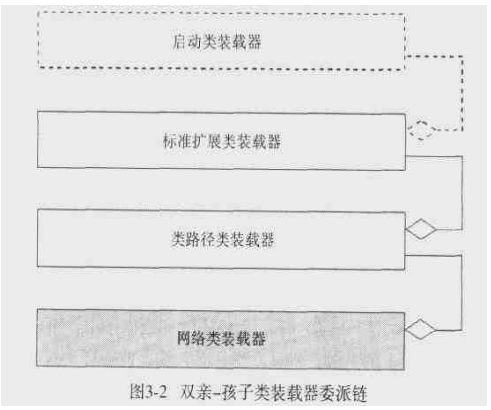
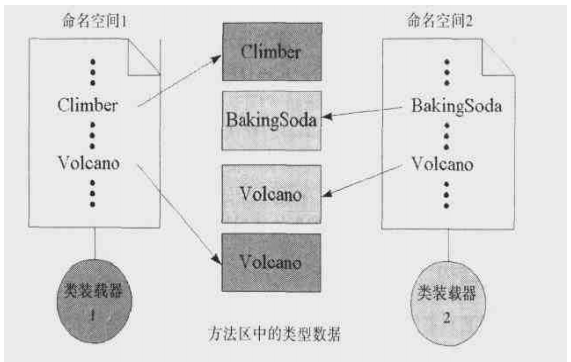
装载class
ClassLoader
- findClass,loadClass
- defineClass
- resovleClass
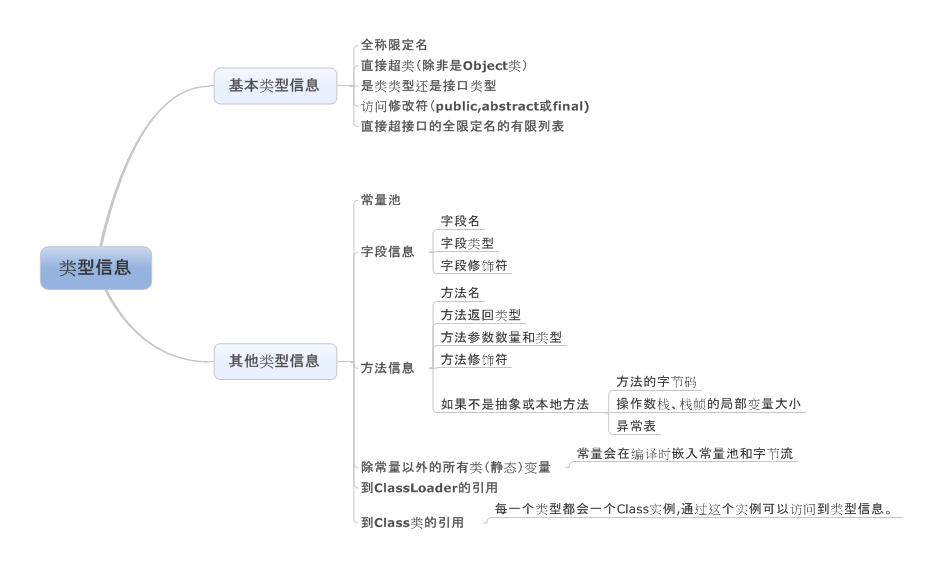
方法区
存储加载的类型信息
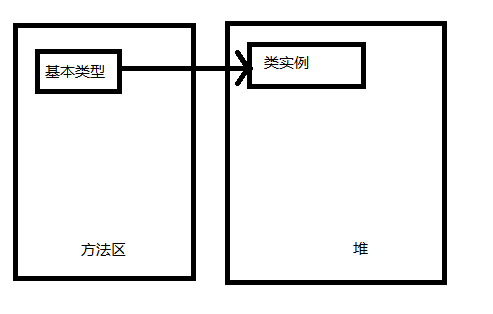
堆
存储类实例和数组
垃圾收集
规范要求提供垃圾收集功能,但是不强求收集算法。
对象的内部表示
两种可选的模型:
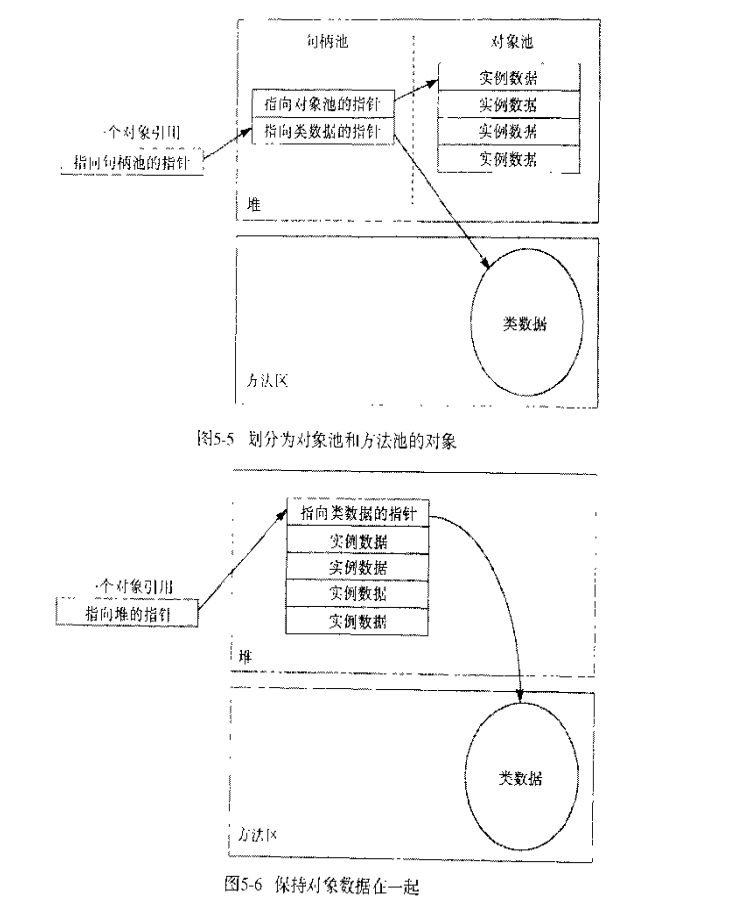
一定是需要有一个类型信息的引用。因为:
- 强制转型时需要检查;
- 引用并不一定引用真正的类型信息,在动态绑定时查找需要。
对象的特殊信息
方法表。用于加快方法访问。
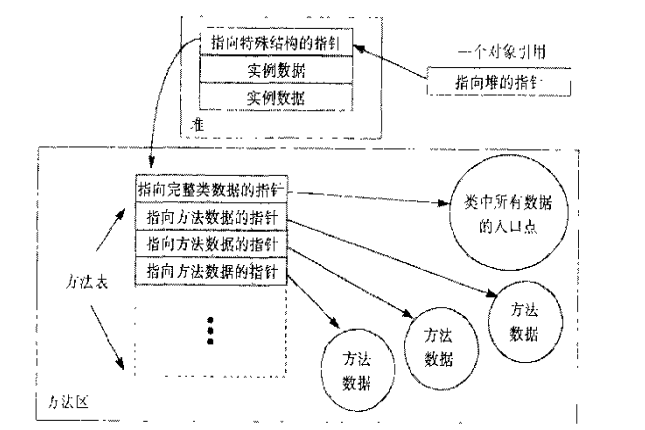
锁及其wait Set
每一个对象都可以当做锁。但是,并不是每一个对象都会使用到,所以有可能把所有锁保存在以对象地址为索引的搜索树中。
wait set也是同样的原理。
垃圾收集标志
是否被回收了,是否调用finalizer方法等。
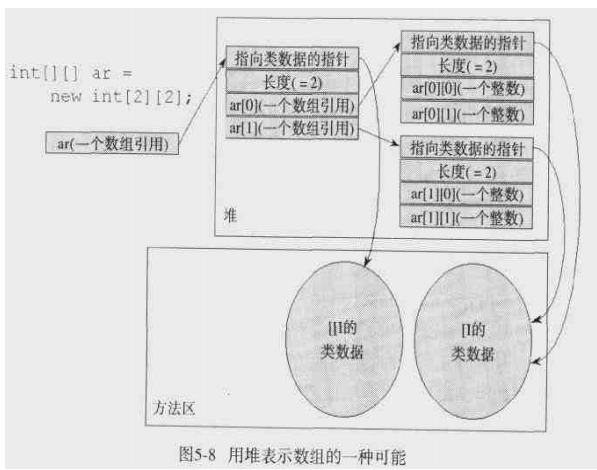
数组对象的内部表示
数据对象也是对象
程序计数器(PC)
- 每一线程都有独立的PC
- PC的长度为一个字(word).既可以保存一个引用,也可以保存一个returnAdress
- PC指向下一条指令的地址(可能是内存地址,也可能是相对偏移量),如果是本地方法,则为undefined
Java栈
- Java栈的基本单位是栈帧,只有两种操作,压栈跟出栈
- 每一次方法调用都是一个栈帧。当前方法的栈帧称为当前帧,当前方法所属的类称为当前类,当前类的常量池称为当前常量池
- 每种方法返回(出栈),一个是return,一个是抛出异常
- 栈数据是私有的,其他线程是无法访问的
栈帧
由三部分组成:
- 局部变量区
- 操作数栈区
- 帧数据区
其中,局部变量区和操作数栈的大小在编译期已经确定。
局部变量区
局部变量是以字长为单位的数组,包括了方法实参和运行过程中的局部变量。每一个基本类型(long跟double除外)和引用占一个字,而long和double占用两个字
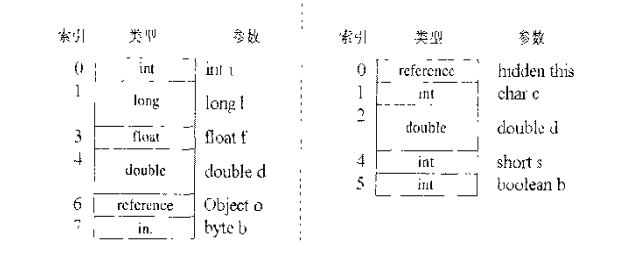
左边是一个类方法,而右边是一个实例方法。实例方法的第一个变量是对自身的引用。
操作数栈区
操作数栈也是以字长为单位的栈,用于存储字节码执行过程的参数、结果等。两个数的相加过程:

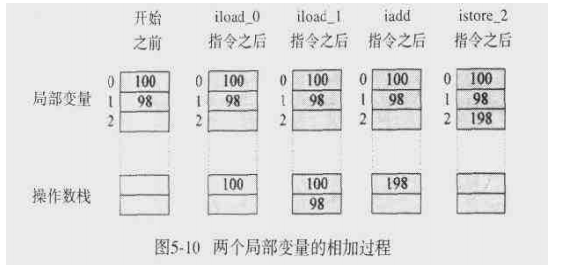
帧数据区
用于支持常量池解析、正常方法返回、异常派发及其他一些任务。
常量池解析
例子:
public class Main { private final static int n = 3; public static void main(String[] args) { int a = n + 1; } }常量池为:
Constant pool: #1 = Class #2 // com/troy/Main #2 = Utf8 com/troy/Main #3 = Class #4 // java/lang/Object #4 = Utf8 java/lang/Object #5 = Utf8 n #6 = Utf8 I #7 = Utf8 ConstantValue #8 = Integer 3 #9 = Utf8 <init> #10 = Utf8 ()V #11 = Utf8 Code #12 = Methodref #3.#13 // java/lang/Object."<init>":()V #13 = NameAndType #9:#10 // "<init>":()V #14 = Utf8 LineNumberTable #15 = Utf8 LocalVariableTable #16 = Utf8 this #17 = Utf8 Lcom/troy/Main; #18 = Utf8 main #19 = Utf8 ([Ljava/lang/String;)V #20 = Utf8 args #21 = Utf8 [Ljava/lang/String; #22 = Utf8 a #23 = Utf8 SourceFile #24 = Utf8 Main.java正常方法返回
当return时,需要出栈,并将PC设置被调用方法的指令,并将返回值压入栈(如果有返回值)
异常派发
方法基本信息会保存一个异常表,表示每一个catch保护的范围。当异常发生的时候,需要查找此表,看是否有合适的处理(catch代码),如果没有,则出栈,并在当前栈执行同样的判断。
其他任务
比如调试信息(行号等)
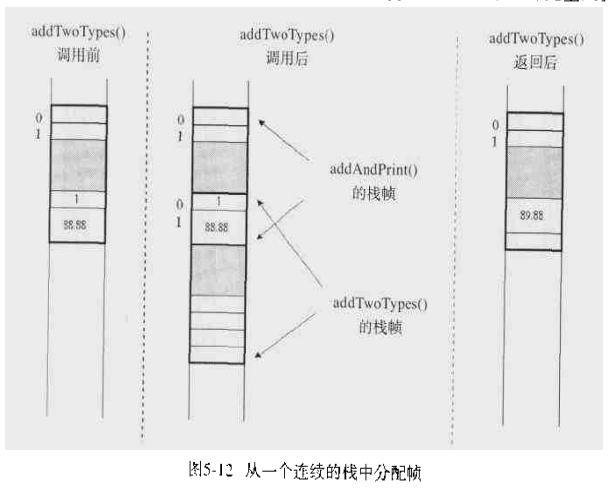
栈帧的可能实现方式
- 每一个栈帧都是独立的内存空间
相邻两个栈帧间交叠一部分区域。将前一个栈帧的操作数栈区的栈顶作为下一个栈帧的局部变量区的起始。如:
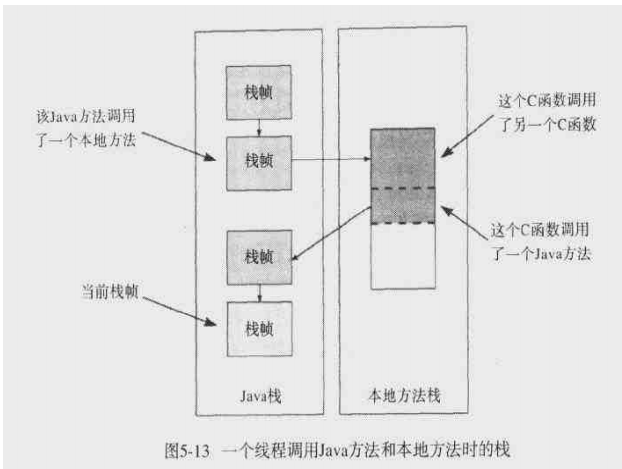
本地方法栈
当线程调用本地方法的时候,就进入一个不受虚拟控制的世界。本地方法本质上是依赖于实现的,虚拟机设计者可以自由地决定Java如何调用本地方法。
一个C模型的例子:
对于本地方法的要求:

执行引擎
执行引擎是JVM的核心,系统的行为就是由它执行字节码流决定的。每一个用户线程其实都是一个执行引擎实例(垃圾收集线程等系统线程不一定)。
指令集
指令=操作码 + 0到多个操作数 , 一个操作码一个字的长度。操作数可以来自常量池、操作数栈以及局部变量表。
例子:
public class Main { private int m = 0; public void test() { m++; int i=0; for(int j=0;j<10;j++){ i++; } } }编译后的test方法的字节码:
Code: stack=3, locals=3, args_size=1 0: aload_0 1: dup 2: getfield #12 // Field m:I 5: iconst_1 6: iadd 7: putfield #12 // Field m:I 10: iconst_0 11: istore_1 12: iconst_0 13: istore_2 14: goto 23 17: iinc 1, 1 20: iinc 2, 1 23: iload_2 24: bipush 10 26: if_icmplt 17 29: return- iconst_0 的操作数是0,它是往栈顶添加常量0
- getfield #12 的操作数是常量池的符号
- iinc 的操作数是局部变量
- iadd 的操作是1,是取栈顶的数+1,并且再压回栈顶。
影响指令集设计的几个方面
- 为了达到平台无关性,指令集的设计是以栈为中心的,大部分指令的操作数都是基于操作数栈的,而局部变量通常被视为类似于寄存器,而常量池主要是存储的一些符号。
以栈为中心还有另一个目的是(没看懂。。。*)

字节码的紧凑性。但是严格的字节对齐,牺牲了一些优化的可能性。
- 字节码的可验证性。为了安全,在加载的class的时候,需要进行字节码验证。为了更好的支持这个过程,相当部分指令需要指明指令的类型(方便校验),比如store操作,对于int是istore,对于float是fstore,虽然它们的动作是一模一样,甚至可能实现也是一样的。
决定下一条指令的三种可能
- 紧跟在当前字节码后的下一条字节码
- goto 或 return 指令
- 抛出异常时,需要检查异常表,决定是处理还是抛出
执行技术
- 直接解释字节码。
- 即时编译。全部转换成本地代码)
- 自适应编译。把最频繁的10-20%代码编译成本地代码。
- 硬件芯片编译。
线程
Java定义了线程模型,目标是希望可以在不同的体系结构上实现它。
- 线程的优先级是非常宽松的,可能对应本地的线程级别,也可以是另外的实现。优先级仅仅是表示这种时间片分配的期望,而非一个严格的标准。
- 线程必须支持同步的两个方面: 对象锁定 以及 线程等待与通知
- 线程的对于基本类型的操作必须是原子性的,除了非volatile的double和long(因为它们占了两个字,所以有可能是两步操作)
- 等等